






, il faut enclencher une véritable « révolution culturelle européenne »")



 grimpe de 580% : les raisons de cette explosion")



 : un coup dur ?")






La légende
Un homme doit connaître ses limites.
Dirty Harry, Magnum Force
Mon analyse porte davantage sur le comment et le pourquoi des choses, plutôt que de trouver un processus qui rapporte beaucoup d’argent et tout ce que cela implique.
Au début de 2019, j’ai lancé un projet de retraite visant à mettre au point une solution logicielle pour soutenir l’analyse objective des marchés boursiers. J’ai écrit des articles occasionnels pour Seeking Alpha afin de documenter mon travail, tout en suggérant comment les informations pourraient être utiles dans la prise de décision en matière d’investissement et de commerce.
Dans cet article, je vais faire la démonstration d’un moteur d’analyse de stratégie simple et complexe et montrer comment certains des effets négatifs de la récente apocalypse auraient pu être atténués en prêtant attention aux détails techniques révélés par le moteur en conjonction avec une appréciation de l’environnement du marché.
Science des données et statistiques
Le domaine émergent de la science des données est la discipline universitaire la plus importante pour la finance.
La science des données est un domaine interdisciplinaire qui utilise des méthodes, des processus, des algorithmes et des systèmes scientifiques pour extraire des connaissances et des idées de [data].
La pertinence des statistiques fait l’objet d’un débat :
De nombreux statisticiens, dont Nate Silver, ont fait valoir que la science des données n’est pas un nouveau domaine, mais plutôt un autre nom pour les statistiques.[12] D’autres affirment que la science des données se distingue des statistiques parce qu’elle se concentre sur les problèmes et les techniques propres aux données numériques.[13]Vasant Dhar écrit que les statistiques mettent l’accent sur les données quantitatives et la description. En revanche, la science des données traite de données quantitatives et qualitatives (par exemple des images) et met l’accent sur la prévision et l’action.[14]Andrew Gelman, de l’université de Columbia, et le spécialiste des données Vincent Granville ont décrit les statistiques comme une partie non essentielle de la science des données.[15][16]
Bien qu’étant un fan de Nate Silver, je suis d’accord avec la vision non essentielle des statistiques, du moins dans le domaine financier. La théorie des probabilités statistiques est d’une validité douteuse pour expliquer l’évolution du cours des actions ; peut-être que les statistiques sont excellentes si vous êtes un acheteur pour une épicerie. Le sujet est complexe, mais il est utile de comprendre les contours généraux du débat.
Il va sans dire qu’il y a un peu d’animosité bon enfant mêlée aux questions académiques légitimes ; cela rappelle le cliché du football :
Les deux équipes ne s’aiment tout simplement pas.
La plupart de mes recherches s’inscrivent dans la sous-discipline de la finance informatique.
Finance informatique est une branche de l’informatique appliquée qui traite des problèmes d’intérêt pratique dans le domaine de la finance.[1] Quelques définitions légèrement différentes sont l’étude des données et des algorithmes actuellement utilisés dans la finance[2] et les mathématiques des programmes informatiques qui réalisent des modèles ou des systèmes financiers.[3]
Il est intéressant de noter que la définition est assez souple. L’accent est mis sur appliqué l’informatique. Cette orientation est confortable pour moi car j’ai un trouble de l’apprentissage qui me rend difficile l’absorption d’informations dans une salle de classe ou par la lecture. En général, je travaille en créant ou en interprétant des concepts et j’essaie ensuite de déterminer à quoi ressemblent les charlatans qui en résultent.
L’analyse technique traditionnelle du marché mérite à juste titre sa réputation académique douteuse. La manière la plus raisonnable de la rendre au moins à la limite du respectable est de changer d’orientation et de passer de la quasi-statistique à la finance computationnelle.
La science des données et ses sous-divisions devraient être un domaine passionnant à l’avenir.
La première chose qu’ils vous enseignent
Sam : Chaque fois qu’il y a un doute, il n’y a pas de doute. C’est la première chose qu’on vous apprend.
Vincent : Qui t’a appris ?
Sam : Je ne m’en souviens pas. C’est la deuxième chose qu’on vous apprend.
Ronin
Binaire
Le système moderne de nombres binaires, base du code binaire, a été inventé par Gottfried Leibniz en 1689… Le système de Leibniz utilise les 0 et les 1, comme le système moderne de nombres binaires. Leibniz a rencontré le I Ching par le jésuite français Joachim Bouvet et a noté avec fascination comment ses hexagrammes correspondent aux nombres binaires de 0 à 111111, et a conclu que cette cartographie était la preuve des grandes réalisations chinoises dans le genre de mathématiques binaires visuelles philosophiques qu’il admirait.[2][3] Leibniz voyait les hexagrammes comme une affirmation de l’universalité de sa propre croyance religieuse.[3]
Les questions théologiques sont profondes et fascinantes, mais trop intéressantes pour être traitées dans cet article.
Binaire à Hexadécimal
La conversion de valeurs binaires en hexadécimal est l’un des piliers de la civilisation moderne (l’algèbre linéaire pourrait en être un autre).
L’hexadécimal est un système de nombres de base et de position utilisé en mathématiques et en informatique. Il a une base de 16 et utilise 16 symboles alphanumériques uniques avec les chiffres de zéro à 9 pour se représenter et les lettres A-F pour représenter les valeurs 10 à 15.
L’hexadécimal est un moyen plus facile de représenter des valeurs binaires dans les systèmes informatiques car il réduit considérablement le nombre de chiffres, un chiffre hexadécimal équivalant à quatre chiffres binaires.
Dans le bon vieux temps, il était essentiel de gagner un peu de place. Un avantage théorique plus important est que les opérations hexadécimales peuvent à la fois simplifier et améliorer la logique du programme.
Les informations sont codées en attribuant une valeur à chacun des quatre chiffres binaires (bits). Le bit le plus à droite = 1, le suivant = 2, le suivant = 4, et le plus à gauche = 8. Personnellement, je commence à gauche lorsque j’évalue ces bits, ce qui est peut-être normal, mais les valeurs numériques restent les mêmes.
Par exemple :
- 1111 binaire = F = (8 + 4 + 2 + 1) F est appelé Fox si vous l’utilisez dans une conversation.
- 1100 binaire = C = (8 + 4) C s’appelle Charlie.
- 0011 binaire = 3 = (2 + 1) 3 = F – C
- 0000 binaire = 0 = F- F
Les noms des lettres des nombres suivent les noms de l’alphabet phonétique utilisé par l’armée américaine pendant la Seconde Guerre mondiale, par opposition à la norme actuelle de l’OTAN.
Probabilités
Un seul caractère hexadécimal encode toutes les possibilités de tirer à pile ou face quatre fois. Les stratégies de marché sont basées sur une ou plusieurs conditions binaires (vrai/faux). Il est logique d’utiliser la structure de probabilité responsable de la civilisation moderne pour analyser les stratégies.
Si les probabilités agissent normalement (comme si l’on tirait à pile ou face), chaque possibilité (chaque caractère de l’hexagone) apparaîtra régulièrement dans un ensemble de données raisonnablement important. Cela n’arrive pas avec les prix des actions. Dans la logique de FoxForce5 décrite ci-dessous, des séquences comme queue tête tête queue et tête queue queue tête se produisent très rarement ; alors que des séquences comme queues queues queues queues queues et têtes têtes têtes têtes têtes sont assez courantes.
Peut-être que la plupart de ces comportements résultent du fait que les indicateurs ont tendance à évoluer de la même manière parce qu’ils sont tous basés sur le prix. La meilleure façon d’étudier les probabilités d’évolution des prix des actions est d’utiliser des portes logiques.
A porte logique est un dispositif électronique idéalisé ou physique mettant en œuvre une fonction booléenne, une opération logique effectuée sur une ou plusieurs entrées binaires qui produit une seule sortie binaire
La comptabilité par états finis est une abstraction du concept académique bien connu de machines à états finis. Les machines à états finis interviennent spécifiquement dans la définition des portes logiques. Par exemple :
Les FSM sont l’un des sujets les plus importants dans le domaine de l’électronique numérique. Il fournit une méthodologie formelle permettant à un concepteur de traduire les spécifications d’un circuit de commande numérique en circuits réels.
Moteur de stratégie
Si vous pouvez reprendre l’épée en trois mouvements, je vous accompagnerai.
Jen, Tigre accroupi, Dragon caché
Un moteur de stratégie pour Excel en VBA qui peut gérer de multiples décisions binaires a été décrit récemment dans Peak and Trough Analysis. Cet article traite des modifications apportées au moteur qui non seulement simplifient le codage, mais augmentent également sa puissance et sa sophistication.
Emboîté pour les boucles, les réseaux et les cordes
La programmation basée sur une grille exige une certaine habileté dans la manipulation des lignes et des colonnes. Ceci, à son tour, exige la maîtrise de l’imbrication pour les boucles. Les boucles imbriquées fournissent la logique d’indexation pour manipuler les données dans les lignes, les colonnes, les chaînes de caractères et les tableaux. Habituellement, les tableaux sont unidimensionnels, c’est le premier effort de développement que j’ai eu où des tableaux bidimensionnels semblent nécessaires. La logique des lignes et des colonnes est bidimensionnelle. Il existe un grand nombre de vidéos YouTube décentes sur ces sujets. Le secret pour devenir bon est pratique.
Structure des données sur l’historique des prix
L’historique des prix est stocké dans un tableur qui porte le même nom que le symbole de la valeur. Il ressemble à ceci avant que les conditions ne soient calculées :

SPY – Créé par l’auteur avec des données de Norgate
Le tableau montre l’historique des prix du SPY pour les 10 derniers jours. Je télécharge généralement les 2000 derniers jours de transactions pour plusieurs symboles chaque jour et j’en analyse un tas simultanément.
La récupération des données s’appelle le chargement. Comme les données sont reconstruites quotidiennement, il n’y a pas de besoin évident de base de données. Les données sont reconstituées parce qu’il est préférable (le mieux est un autre mot pour le plus facile) d’utiliser les prix ajustés des dividendes et du fractionnement. Cette étape ennuyeuse est effectuée par NorgateData dans ce cas.
Norgate conserve les données sur les prix de fin de journée sur l’ordinateur de l’utilisateur. Il est possible d’obtenir des données gratuitement, mais Norgate coûte environ une tasse de café par jour. Si vous ne vivez pas dans la rue, cela en vaut la peine.
Norgate fournit les données par le biais de la colonne Fermer. WPrice est un prix pondéré (Ouvert + Haut + Bas + Fermeture + Fermeture) * 0,2. N01 est le logarithme naturel du rendement quotidien.
Les colonnes de condition sont calculées après le chargement de l’historique des prix, dans ce qu’on appelle la construction.

SPY – Créé par l’auteur avec des données de Norgate
Certaines des colonnes sont cachées pour des raisons de lisibilité.
Le tableau présente 8 longueurs différentes de moyennes mobiles exponentielles (E) et de moyennes mobiles simples (M). Après le calcul de l’indicateur donné, celui-ci est transformé en un nombre positif ou négatif par la formule :
(WPrice – Moyenne) / WPrice * 100
Un nombre positif indique que le prix actuel pondéré est supérieur à la moyenne, les nombres négatifs ou zéro sont considérés comme inférieurs.
Construire le cadre de l’hexagone
La façon la plus évidente de les analyser dans un cadre hexagonal est la longueur. Si nous analysons une seule longueur à la fois, il y a au moins deux types de situations qui méritent d’être examinées :
- Prix actuel supérieur ou inférieur à la moyenne
- Moyenne actuelle supérieure ou inférieure à la moyenne précédente
Il en ressort 4 résultats possibles pour chaque longueur.
La logique de la stratégie précédente pouvait gérer cela, mais chaque type de décision différent ajoute à la complexité de l’algorithme de la stratégie. Cela peut sembler trivial, mais la complexité supplémentaire augmente de manière exponentielle. Une bonne technique exige de contrôler la complexité. C’est le problème que la solution Hex est conçue pour résoudre.
La plupart des développeurs (même les bons – peut-être tous les autres) ne pensent pas de cette façon. C’est-à-dire que, confrontés au défaut de conception de la complexité supplémentaire, ils choisiront de l’ignorer. C’est compréhensible, bien sûr, mais parfois la solution de facilité n’est pas la meilleure.
Les vraies fausses décisions sont retirées de l’algorithme de stratégie et placées dans l’étape de construction. L’étape de construction détermine le vrai faux statut et transmet les résultats de son calcul à l’algorithme de stratégie dans un cadre Hex.
Problèmes techniques liés au cadre hexagonal
Les colonnes de la feuille de calcul sont classées par type d’indicateur et ensuite par longueur, c’est-à-dire E3, E7, E16… M3, M7…
Nous voulons construire un personnage d’hexagone pour chaque longueur. Par exemple, si la longueur est de 3 :
- 8 bit = E3A – Le prix est supérieur à E = on
- 4 bit = M3A – Le prix est supérieur à M = on
- 2 bit = E3U – E est en hausse par rapport à la veille = on
- 1 bit = M3U – M est en hausse par rapport à la veille = on
Une fois que cela est résolu, la même routine doit être effectuée pour la durée suivante, etc.
Une solution consiste à changer les chiffres en 1 ou 0 pour chacune des deux conditions. Il existe 8 longueurs différentes pour 2 types d’indicateurs. 8 * 2 = 16. Nous recherchons 2 conditions (au-dessus/en dessous et en haut/en bas). 16 * 2 = 32. 32 caractères binaires peuvent être encodés en 32/4 = 8 caractères hexadécimaux.
Cette opération est plus facile à réaliser avec l’ordre existant, de sorte que les réponses binaires aux deux premières questions de toutes les longueurs sont chargées sans le drame potentiel d’un For Loop imbriqué :
- xwa1 = « 00000000 » & « 00000000 » & « 00000000 » & « 00000000 »
- Pour xw = 1 à 16
- Si Feuilles de travail (symbole), cellules (x1, xw + x11) > 0, alors _Mid(xwa1, xw, 1) = « 1 ».
- Si Feuilles de travail(Symbole).Cellules(x1, xw + x11) > _Feuilles de travail(Symbole).Cellules(x1 – 1, xw + x11) Alors _Moyen(xwa1, xw + 16, 1) = « 1
- Suivant xw
x11 est une constante qui contient le décalage par rapport à la première colonne de données. La partie la plus complexe consiste à effectuer le remaniement de la longueur après le chargement binaire :
- Pour xw = 1 à 8
- Pour xw1 = 1 à 4
- xw2 = (xw1 – 1) * 8
- xwaX = Mid(xwa1, xw + xw2, 1)
- Mid(xwa2, xw1, 1) = xwaX
- Suivant xw1
- xwa3 = Feuille de travailFonction.Bin2Hex(Arg1:=xwa2)
- xEM = xEM & xwa3
- Suivant xw
xwa1 est la chaîne de nombres binaires de 32 caractères. xwa2 lorsque xw = 1 est la chaîne binaire de longueur = 3. Elle est convertie en un seul caractère Hex avec la fonction Bin2Hex d’Excel. Il stocke toutes les informations ci-dessus/en dessous et en haut/en bas des 16 colonnes.
Il m’a fallu quelques heures pour coder et tester cela, mais il a fallu un effort considérable pour arriver à ce stade. Simplifier le code vaut bien un petit effort, je suppose.
La routine consiste en quelques déclarations plus longues qu’il ne le faudrait, du moins une partie d’entre elles en raison des déficiences du traitement des chaînes VBA. Le site Mid est important pour la gestion des chaînes de caractères, car il nous permet de traiter une chaîne de texte comme un tableau. L’implémentation VBA de la gestion des chaînes de caractères (y compris le formatage) est un peu maladroite mais pas trop mauvaise.
Le moteur de stratégie peut générer une analyse de performance à partir des données suivantes :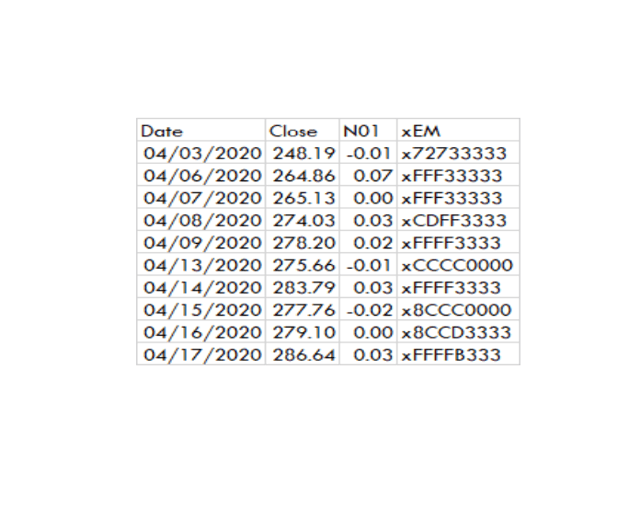
SPY – Créé par l’auteur avec des données de Norgate
Après le x dans la colonne xEM, les caractères hexadécimaux indiquent les différentes positions techniques pour la longueur correspondante. Par exemple, sur 4/3, le 7 après le x est le statut des moyennes sur 3 jours. Le 7 signifie que le prix est inférieur à la ZME de 3 jours, supérieur à la ZME de 3 jours et que la ZME et la ZME sont toutes deux en hausse par rapport à la journée précédente.
L’algorithme ne se soucie pas de la signification des chiffres, ni même de savoir si les conditions sont vraies ou fausses.
Colonne hexagonale simple
Un coup d’œil aux données ci-dessus montre que Fox et Charlie apparaissent le plus souvent avec les compléments de leur 1 ; 0 et 3.
Les compléments sont utilisés dans les ordinateurs numériques afin de simplifier l’opération de soustraction et pour les manipulations logiques.
On trouve le complément d’un nombre en changeant tous les 1 en 0 et tous les 0 en 1.
Le tableau ci-dessous présente les performances cumulées sur l’année de trois grands ETF.

Créé par l’auteur avec des données de Norgate
Les lectures actuelles de xEM sont ajoutées. Il faut un peu de pratique pour lire xEM, mais cela vaut la peine de faire quelques efforts car il contient 32 faits relativement importants sur l’état actuel du marché. Ces informations sont trop complexes pour être comprises visuellement si elles sont affichées sur un graphique.
La question la plus importante est de savoir si un ordinateur peut comprendre l’information. Il ne fait aucun doute qu’un ordinateur peut traiter plus facilement et plus efficacement le xEM qu’un affichage visuel. D’une certaine manière, les problèmes de mesure de la position actuelle d’un prix ressemblent à la mécanique quantique.
Les numéros de FoxForce5 sur 3 jours sont indiqués ci-dessous.
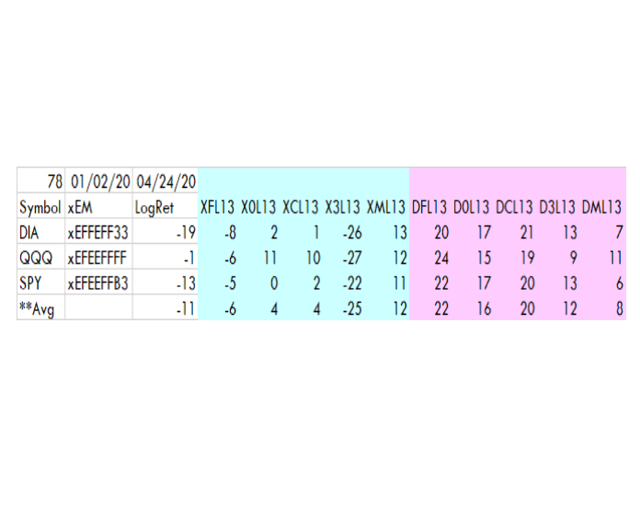
Créé par l’auteur avec des données de Norgate
Le journal naturel du retour pour chaque condition est en bleu. Le rose est le nombre de jours que chaque condition a duré. La raison pour laquelle l’algorithme est appelé FoxForce5 est qu’il y a 5 conditions hexadécimales qui sont analysées : F, C, 3, 0 et M. M signifie « Divers ».
Cette routine calcule les rendements sur la base d’une seule colonne de code xEM. Les conventions d’appellation sont essentielles. Les conventions de nommage sont modifiées au fur et à mesure que la compréhension de l’application par le développeur change (s’améliore). Elles changent légèrement entre l’affichage ci-dessus et la routine plus avancée qui sera présentée ci-dessous.
Les noms des stratégies commencent par X suivi du caractère hexagonal analysé. Il est suivi d’un L (pour la longueur) et ensuite de la longueur. Le total des lignes bleues est exactement égal à LogRet, mais comme les décimales sont supprimées, la vérification manuelle de celles-ci pourrait être décalée de 1.
Les colonnes roses indiquent le nombre total de jours pour chaque condition, les chiffres se croisant avec les 78 dans le coin supérieur gauche.
Les mauvaises performances de X3L13 sont remarquables. XFL13 et X3L13 sont les deux stratégies des cinq présentées qui ont perdu de l’argent cette année. Je ne recommande pas d’aller plus loin la prochaine fois que X3L13 apparaît.
Des longueurs plus courtes de XF montrent un profit YTD. Dans ce cas, la longueur supplémentaire a fait qu’elle est restée longue un peu plus tard que les moyennes à court terme.
Colonnes hexagonales multiples
Comme il y a 5 seaux (FC30M) pour une seule colonne, la combinaison de 2 colonnes en nécessitera 25, alors que 3 colonnes en nécessiteront 125. Ce type d’analyse nécessite la présentation des résultats pour une sécurité à la fois. C’est un problème humain, il est difficile d’apprendre à un ordinateur si vous ne savez pas ce que vous faites.
Si nous devions nous préoccuper de chaque possibilité, 2 colonnes nécessiteraient 256 (16 * 16) et 3 colonnes 4096 (16 * 16 * 16). La réduction du nombre pratique de probabilités est un avantage substantiel.
Le tableau ci-dessous présente une analyse en deux colonnes :
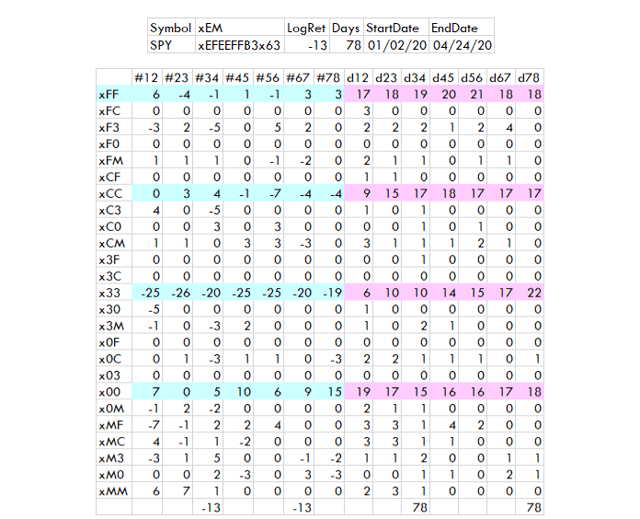
Créé par l’auteur avec des données de Norgate
Notez que la convention d’appellation a dû être modifiée car les données sont présentées verticalement au lieu d’être présentées horizontalement.
La longueur des colonnes représentée par la numérotation est une variable, dans ce cas, les longueurs utilisées le sont :
- 3
- 7
- 13
- 21
- 31
- 43
- 57
- 73
L’utilisation de la longueur réelle commence à prendre trop de place pour l’en-tête, de sorte que les en-têtes de colonne définissent les numéros de colonne analysés. Par exemple, #12 signifie que les colonnes 1 et 2 de xEM sont utilisées.
Au lieu d’un seul personnage d’hexagone, il y en a maintenant deux.
Les totaux des colonnes se croisent au pied des totaux du haut. C’est-à-dire, LogRet = -13 et Jours = 78. Plusieurs colonnes sont totalisées dans le tableau pour le montrer.
Le mal de x33 par rapport au bien de x00 est un peu exagéré dans ce tableau à court terme. x33 est l’état majeur qui se produit après x00. De même, xCC est un état majeur courant qui apparaît après xFF. xCC est, en général, haussier parce que le marché a reculé mais pas assez pour que les prix passent en dessous des moyennes. x33 est l’opposé, car il se produit lors d’un rallye après une récession plus sévère qui n’avance pas assez pour que les prix passent au-dessus de la moyenne.
Notez également que certaines combinaisons ne se produisent pas, et que d’autres sont très rares.
Le choix du jumelage en fait partie. J’ai décidé d’apparier des moyennes qui sont l’une à côté de l’autre. C’est plus simple que les autres choix à deux colonnes, car il s’agit simplement de x et (x + 1).
Le marché baissier de 2001-3
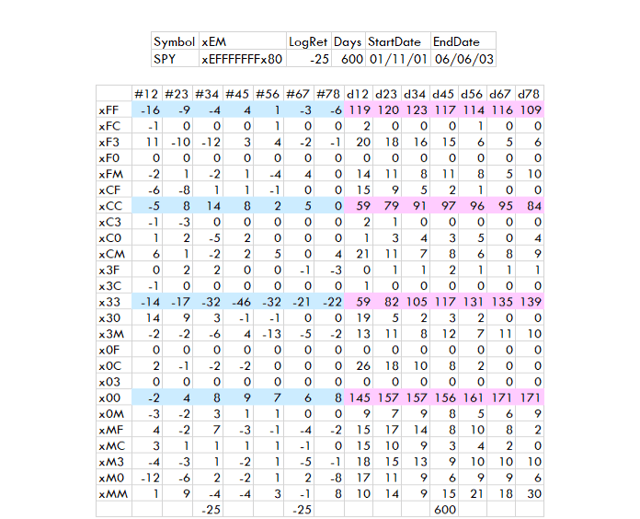
Créé par l’auteur avec des données de Norgate
La période 2001-2003 a été le dernier long marché baissier. Les pertes se sont concentrées en x33 comme en 2020. Le nombre de jours pour x33 et x00 était supérieur à xFF et xCC.
Crise financière 2008-9
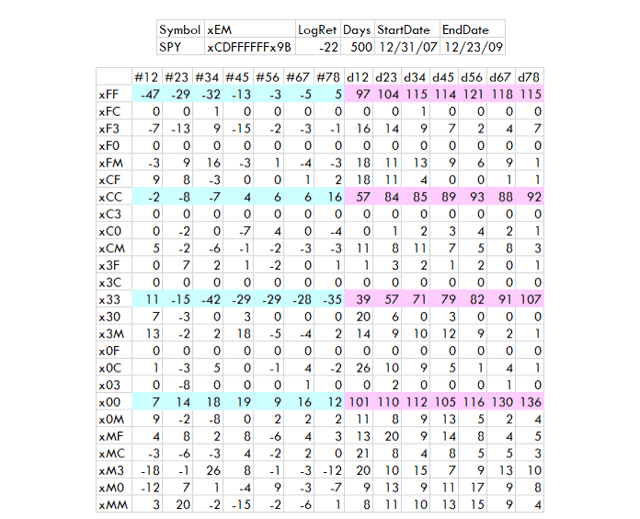
Créé par l’auteur avec des données de Norgate
L’année 2008 montre une distribution des rendements quelque peu similaire à celle de 2001 et 2020. Un xFF très faible, un x33 habituellement faible et un bon résultat à partir de x00.
2019
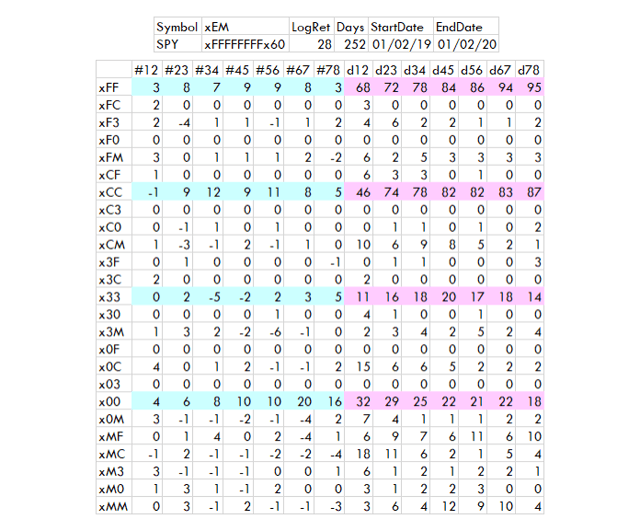
{kind=link}
Créé par l’auteur avec des données de Norgate
Le tableau final montre les rendements d’un environnement de marché non baissier. x33 semble un peu plus faible que d’habitude pour les environnements normaux. L’achat et la conservation pourraient être battus en évitant x33 et en investissant pendant x00 xCC et xFF. C’est un peu inhabituel.
Commentaires
La structure hexagonale semble être un excellent outil d’analyse. La question initiale, qui consistait à trouver un moyen d’afficher l’état actuel du marché dans un espace restreint, a été, de manière assez surprenante, facilement adaptable à des fins de calcul.
Une réflexion doit être menée sur la sélection et l’enchaînement des conditions. Nous avons eu la chance d’avoir les moyennes mobiles à portée de main, car elles semblent correspondre assez bien à la structure cartographique 8,4,2,1.
Les conditions n’ont pas besoin d’être techniques, toute condition binaire définie peut être analysée.
FoxForce5 est un prototype destiné à illustrer les avantages d’une orientation informatique du marché.
Lors de l’action négative sur le marché de la fin 2018, x33 s’en est assez bien sorti et de graves pertes ont été enregistrées avec x00.
L’action actuelle du marché semble similaire à celle de début 2019 :

Les bougies de mars et avril 2020 ressemblent aux bougies de décembre 2018 et janvier 2019 sur stéroïdes.
290 environ, c’est le retracement de 61,8% de la Fib et cela correspond à la moyenne mobile simple de 13 mois. Je pense que la moyenne mobile de 39 mois constituerait un soutien décent autour de 265 si les choses tournent mal, mais le potentiel de hausse pour compenser ce risque est un peu mince.
Divulgation : Je suis/nous sommes long(e)s SPY. J’ai écrit cet article moi-même, et il exprime mes propres opinions. Je ne reçois aucune compensation pour cela. Je n’ai aucune relation d’affaires avec une entreprise dont les actions sont mentionnées dans cet article.
Divulgation supplémentaire : Il a été couvert un peu longtemps dans cet environnement.
